今年5月和10月,航行连续发布了两篇关于AI安全的原创研究《拥抱AI,网络安全的机会在哪里》和《LLM时代,你应当认识的三家AI安全厂商》。随着时间推移小编发现,我们的观点得到了越来越多人的认同,许多头部券商和咨询公司会公开引用或私下参考我们关于AI安全的观点。今天,小编与大家分享更多关于AI安全行业的看法。也欢迎大家通过各种方式与我们探讨。
写在前面的话
认知的演进和深化是需要时间的。通常认为,2014年的一篇《Explaining and Harnessing Adversarial Examples》让学术界关注到AI安全,2017年的一篇《One Pixel Attack for Fooling Deep Neural Networks》让产业界关注到AI安全。随着2023年大语言模型及其应用的爆发,各类AI应用渐次落地并承载了越来越多的商业价值,AI开发和使用过程中的风险和危害逐渐暴露出来。而小编坚信,2024年会是国内投资界聚焦到AI安全的元年。
事实上,2023年10月到年底的短短几个月时间,海外已有至少11家AI安全初创企业获得融资,而在此之前,AI安全赛道的融资并不密集。不难看出,这一新兴赛道在海外已经有越来越多创业者和投资人入局。站在国内的语境下,AI安全赛道最大的投资逻辑是,它作为典型的交叉行业,同时受惠于增长性行业(AI)和防御性行业(安全)的行业逻辑。
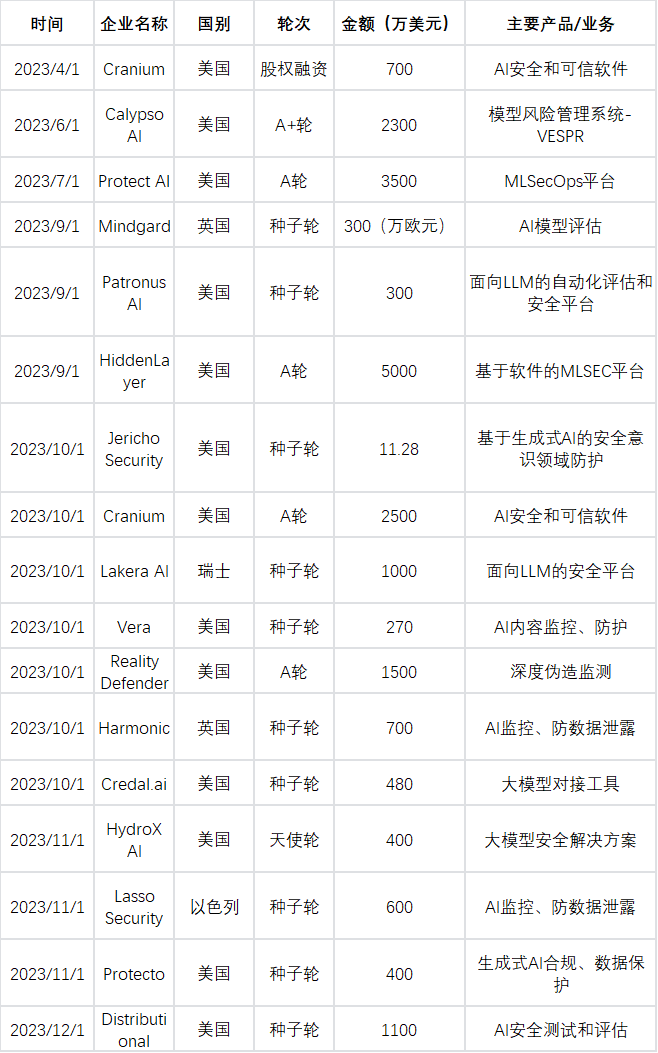
由2023年的一系列融资交易可见,AI安全在产业层面还处于早期起步阶段,创业企业主要集中在种子轮到A轮之间。其实,产业界关于AI安全的认知也仍在形成过程中。AI安全具体指什么,主要驱动力是什么,也并无统一的观点。以下是小编想与大家分享的一些思考。
AI安全的四大细分赛道
许多厂商都在提出或探索自身积累如何与AI技术进行融合。在全产业链涉及AI安全这一大概念下,小编今年提出了AI安全的四大细分领域,下面作一点复述和补充:
-
安全的AI(模型内生安全),又称为AI Safety或AI Governance。在这一部分中,厂商更主要从模型风险视角,关注AI本身是否对人类和社会而言是安全、可靠和道德的,具体包括合规性评估、算法安全性增强、数据安全性提升、模型/框架安全检测修复、模型功能性能提升等。
-
AI的安全(模型应用安全),可以理解为Security for AI。在这一部分中,厂家主要从AI底层的ML/LLM环境入手,关注如何保护AI在研发和运用过程中不被技术性外部威胁所破坏。
-
AI赋能的业务安全(AIGC安全和内容安全)。这一部分中,AI安全的概念逐渐延伸到AI应用的下游,涉及很多公共安全关注的场景,包括生成式鉴伪、伪造检测、反诈骗,以及内容安全、舆情安全、内容过滤审查等。
-
AI赋能的网络安全(网络安全的转型升级)。这一部分中,厂商从网络安全视角出发,聚焦运用AI技术提升安全产品和能力,如数据分类分级、静态代码分析、流量监测、检测规则生成、安全运营垂直大模型等,这其中安全运营的提质增效是重中之重。
四大细分赛道中,模型内生安全涉及到AI自身机理缺陷的内部风险,是保证模型安全可靠应用的前提;模型应用安全涉及AI在开发和运用过程中面临的外部风险,是保证模型安全可靠应用的基础。以上两个细分赛道将是投资领域关注的重点。后面的探讨主要围绕这两个细分赛道。
AI安全产业的增长性逻辑——技术可信可靠
AI安全行业的产生,源于提升AI技术安全可信可靠的原始需求。
首先,我们需明确AI自身面临“信任危机”的原因,也就是AI自身带来的风险主要有哪些。根据中国信通院发布的《人工智能白皮书(2022年)》,人工智能技术自身特性引发的风险隐患,主要分为以下三类:
-
深度学习模型存在脆弱和易受攻击的缺陷(稳定性/鲁棒性不足)
-
黑箱模型具备高度复杂性和不确定性,算法不透明容易引发不确定性风险(可解释性不足)
-
人工智能算法产生的结果过度依赖训练数据,如果训练数据中存在偏见歧视,会导致不公平的智能决策产生(公平性不足)
关于提升AI安全可靠性,当前研究主要聚焦在提升模型的稳定性、可解释性、隐私保护、公平性等维度上:
稳定性:指模型对未知输入可给出符合预期的输出,可一定程度上抵御复杂环境及恶意干扰。
-
环境因素多变:例如光照强度、视角角度距离、图像仿射变换、图像分辨率都可能会导致AI模型表现不稳定,其根本原因是训练数据难以覆盖现实场景的全部情况。
-
特有攻击:AI模型面临中毒攻击、对抗攻击、后门攻击等特有攻击,例如用对抗样本眼镜干扰人脸识别系统。
可解释性:指以人类可理解的方式解释或展示AI模型的能力,使人们能够追踪、预测和解释AI的决策过程。模型可解释性不足是影响稳定性的原因之一。
隐私保护:模型需要依赖大量数据,数据流转过程及模型本身都有可能泄漏敏感隐私数据。
公平性:模型的公平性不足主要体现在数据层面和技术层面上:受数据采集条件限制,不同群体在数据中所占权重不均衡;在不平衡数据集上训练模型造成模型决策不公平。
随着大模型及相关应用对社会公众提供服务后,AI模型的固有技术风险暴露面正在持续放大。这些风险引发的安全事故,让模型安全问题的“冰山一角”逐渐露出水面——企业违规采集顾客人脸信息用于商业目的、自动驾驶失灵、数据投毒让模型输出有害内容等等。总之,让人工智能健康地发展和应用,提升模型内生安全必不可少。
AI安全产业的防御性逻辑——法律法规和社会治理
除人工智能本身的机理性技术缺陷外,其对现有法律和规范体系、社会治理和公共安全等造成的冲击也是不容忽视的问题。这也成为了较过往数据安全等领域,监管政策出台节奏更快的重要原因。近两年,全球各国已掀起人工智能治理浪潮,相关规范和政策等列举如下:
我国关于人工智能与算法的监管已经初具雏形。《生成式人工智能服务管理暂行办法》(2023年)、《互联网信息服务深度合成管理规定》(2022年)、《互联网信息服务算法推荐管理规定》(2021年)形成了我国AI监管的三足鼎立之势。这三项规章与更上位的《网络安全法》《数据安全法》《个人信息保护法》《科学技术进步法》共同构成了“前《人工智能法》时代”算法与人工智能的监管框架。
-
《互联网信息服务深度合成管理规定》提出“提供具有舆论属性或者社会动员能力的生成式人工智能服务的,应当按照国家有关规定开展安全评估,并按照《互联网信息服务算法推荐管理规定》履行算法备案和变更、注销备案手续。”
-
《生成式人工智能服务管理暂行办法》为七部委联合制定颁布,于2023年8月15日正式施行,是我国首个针对生成式AI行业的规章。该规章明确了人工智能研发者、部署者以及使用者等这几类行业责任主体在服务中的责任与义务,主要包括数据合规、算法合规、算力合规、知识产权合规方面的合规义务。
此外,2023年10月提出的《生成式人工智能服务安全基本要求》(征求意见稿),是我国首个专门针对生成式人工智能提出具体安全要求的国家标准。《基本要求草案》一旦正式颁布,将可用于指引企业遵守《生成式人工智能服务管理暂行办法》的要求。全文共涵盖9个主题,包括:范围,规范性引用文件,术语和定义,总则,语料安全要求,模型安全要求,安全措施要求,安全评估要求,以及其他要求(关键词库,分类模型,生成内容测试题库,拒答测试题库)。
发展可信人工智能已成为全球共识,围绕人工智能全生命周期打造安全可信的AI生态将成为监管机构、行业组织、企业共同实践和努力实现的目标。随着人工智能与实体经济融合程度不断加深,AI安全的相关标准和监管将越来越聚焦到具体的场景上;同时,根据模型应用场景的差异,分类分级可能成为可信人工智能框架构建的方向。对于自动驾驶、智慧医疗、人脸识别等典型关键应用场景,AI安全治理将有侧重加速落地的可能。
结语
当前,我们已经看到一些国内的AI安全企业崭露头角,但全社会建设可信可靠的人工智能生态仍有漫漫长路。这些新兴力量已经成为AI安全行业的星星之火。期待AI安全行业能够随着AI模型大规模落地应用的东风,以指数级的增长,成长为燎原之势。涉及市场空间规模、监管政策趋势、具体投资标的等话题的探讨,欢迎各位与航行线下交流。关于AI安全,你怎么看呢?